Reverse Time Stochastic Differential Equations [ for generative modelling ]
'If I Could Turn Back Time' by Cher (1989)
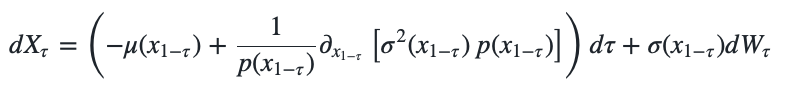
This was my first venture into reverse diffusion and the derivation, although correct, is a bit intricate. I’d recommend this more elegant derivation which is more accessible.
What follows is a derivation of the main result of ‘Reverse-Time Diffusion Equation Models’ by Brian D.O. Anderson (1982). Earlier on this blog we learned that a stochastic differential equation of the form
\[\begin{align} dX_t = \mu(X_t, t) dt + \sigma(X_t, t) dW_t \end{align}\]with the derivative of Wiener process $W_t$ admits two types of equations, called the forward Kolmogorov or Fokker-Planck equation and the backward Kolmogorov equation. The details of the derivation of the forward and backward Kolmogorov equations via the Kramers-Moyal expansion can be found in the previous blog post. For notational brevity we will use the term $\mu(x_t)$ for the drift and $\sigma(x_t)$ as the diffusion parameter and omit the explicit time dependency.
The Kolmogorov forward equation is identical to the Fokker Planck equation and states
\[\begin{align} \partial_t p(x_t) = -\partial_{x_t} \left[ \mu(x_t) p(x_t) \right] + \frac{1}{2} \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right]. \end{align}\]It describes the evolution of a probability distribution $p(x_t)$ forward in time. We can quite frankly think of it as, for example, a Normal distribution being slowly transformed into an arbitrary complex distribution according to the drift and diffusion parameters $\mu(x_t)$ and $\sigma(x_t)$.
The Kolmogorov backward equation for $ s \geq t$ is defined as
\[\begin{align} - \partial_t p(x_s | x_t) = \mu(x_t) \ \partial_{x_t} p(x_s|x_t) + \frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \end{align}\]and it basically answers the question how the probability of $x_s$ at a later point in time changes as we change $x_t$ at an earlier point in time. The Kolmogorov backward equation is somewhat confounding with respect to time as we’re taking the partial derivative with respect to the earlier time step $t$ on which we are also conditioning. But we can think of it as asking ‘How does the probability of $x_s$ at the later point in time $s$ change, as we slowly evolve the probability distribution backwards through time and condition on $x_t$’.
Taking inspiration from our crude example earlier, the backward equation offers a partial differential equation which we can solve backward in time, which would correspond to evolving the arbitrarily complex distribution backwards to our original Normal distribution. Unfortunately there is no corresponding stochastic differential equation with a drift and diffusion term that describes the evolution of a random variable backwards through time in terms of a stochastic differential equation.
This is where the remarkable result from Anderson (1982) comes into play.
The granddaddy of all probabilistic equations, Bayes theorem, tells us that a joint distribution can be factorized by conditioning: \(p(x_s , x_t) = p(x_s|x_t) p(x_t)\) with the time ordering $t \leq s$. Why do we invoke the joint probability \(p(x_s, x_t)\) we might ask? What we’re trying to achieve is to derive a stochastic differential equation that tells us from what values of $x_t$ we can arrive at $x_s$. We can ask ourselves what the partial differential equation would be that describes the evolution of the joint distribution over time. First multiplying both sides of Bayes theorem with minus one and taking the derivative with respect to time $t$, we obtain via the product rule
\[\begin{align} - \partial_t p(x_s, x_t) &= - \partial_t \left[ p(x_s| x_t) p(x_t) \right] \\ &= \underbrace{-\partial_t p(x_s|x_t)}_{\text{KBE}} p(x_t) - p(x_s | x_t) \underbrace{\partial_t p(x_t)}_{\text{KFE}} \end{align}\]into which we can plug in the Kolmogorov forward (KFE) and Kolmogorov backward (KBE) equations,
\[\begin{align} & -\partial_t p(x_s|x_t) p(x_t) - p(x_s | x_t) \partial_t p(x_t) \\ &= \left( \mu(x_t) \ \partial_{x_t} p(x_s|x_t) + \frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \right) p(x_t) \\ & + p(x_s| x_t) \left( \partial_{x_t} \left[ \mu(x_t) p(x_t) \right] - \frac{1}{2} \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] \right) \end{align}\]The derivatives occurring in the backward Kolmogorov equation are
\[\begin{align} \partial_{x_t} p(x_s|x_t) &= \partial_{x_t} \left[ \frac{p(x_s, x_t)}{p(x_t)} \right] \\ & = \frac{\partial_{x_t} p(x_s, x_t) p(x_t) - p(x_s, x_t) \partial_{x_t} p(x_t)}{p^2(x_t)} \\ & = \frac{\partial_{x_t} p(x_s, x_t)}{p(x_t)} - \frac{p(x_s, x_t) \partial_{x_t} p(x_t)}{p^2(x_t)} \end{align}\]The next step is to evaluate the derivative of the products in the forward Kolmogorov equation.
\(\begin{align} \partial_{x_t} \left[ \mu(x_t) p(x_t) \right] & = \partial_{x_t} \mu(x_t) \ p(x_t) + \mu(x_t) \ \partial_{x_t} p(x_t) \\ \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] & = \partial_{x_t}^2 \sigma^2(x_t) \ p(x_t) + 2 \ \partial_{x_t} \sigma^2(x_t) \ \partial_{x_t} p(x_t) + \sigma^2(x_t) \ \partial_{x_t}^2 p(x_t) \end{align}\) Substituting the derivatives of the probability distributions accordingly we obtain \(\begin{align} - \partial_t p(x_s, x_t) = & - \partial_t \left[ p(x_s| x_t) p(x_t) \right] \\ = & -\partial_t p(x_s|x_t) p(x_t) - p(x_s | x_t) \partial_t p(x_t) \\ = & \left( \mu(x_t) \ \partial_{x_t} p(x_s|x_t) + \frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \right) p(x_t) \\ & + p(x_s| x_t) \left( \partial_{x_t} \left[ \mu(x_t) p(x_t) \right] - \frac{1}{2} \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] \right) \\ = & \mu(x_t) \ \partial_{x_t} p(x_s|x_t) \ p(x_t) + \frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \ p(x_t) \\ & + p(x_s| x_t) \partial_{x_t} \mu(x_t) \ p(x_t) + p(x_s| x_t) \mu(x_t) \ \partial_{x_t} p(x_t) \\ & - \frac{1}{2} p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] \\ = & \mu(x_t) \ \left(\frac{\partial_{x_t} p(x_s, x_t)}{\cancel{p(x_t)}} - \frac{p(x_s, x_t) \partial_{x_t} p(x_t)}{p^{\cancel{2}}(x_t)} \right) \ \cancel{p(x_t)} \\ & + p(x_s| x_t) \partial_{x_t} \mu(x_t) \ p(x_t) + p(x_s| x_t) \mu(x_t) \ \partial_{x_t} p(x_t) \\ & + \frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \ p(x_t) - \frac{1}{2} p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] \\ = & \mu(x_t) \ \left(\partial_{x_t} p(x_s, x_t) - \frac{p(x_s, x_t) \partial_{x_t} p(x_t)}{p(x_t)} \right) \\ & + p(x_s| x_t) \partial_{x_t} \mu(x_t) \ p(x_t) + p(x_s| x_t) \mu(x_t) \ \partial_{x_t} p(x_t) \\ & + \frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \ p(x_t) - \frac{1}{2} p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] \\ = & \mu(x_t) \ \left(\partial_{x_t} p(x_s, x_t) - \cancel{p(x_s| x_t) \partial_{x_t} p(x_t)} \right) \\ & + p(x_s, x_t) \partial_{x_t} \mu(x_t) + \cancel{p(x_s| x_t) \mu(x_t) \ \partial_{x_t} p(x_t)} \\ & + \frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \ p(x_t) - \frac{1}{2} p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] \\ = & \underbrace{\mu(x_t) \ \partial_{x_t} p(x_s, x_t) + p(x_s, x_t) \partial_{x_t} \mu(x_t)}_{\text{product rule}} \\ & + \frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \ p(x_t) - \frac{1}{2} p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] \\ = & \partial_{x_t} \left[ \mu(x_t) \ p(x_s, x_t) \right] \\ & + \underbrace{\frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \ p(x_t)}_{(1)} - \underbrace{\frac{1}{2} p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right]}_{(2)} \end{align}\)
In order to transform the partial differential equation above into a form from which we can deduce an equivalent stochastic differential equation, we match the terms of the second order derivatives with the following identity,
\[\begin{align} & \frac{1}{2} \partial_{x_t}^2 \left[ p(x_s, x_t) \sigma^2(x_t) \right] \\ = & \frac{1}{2} \partial_{x_t}^2 \left[ p(x_s | x_t) p(x_t) \sigma^2(x_t) \right] \\ = & \frac{1}{2} \partial_{x_t}^2 p(x_s | x_t) p(x_t) \sigma^2(x_t) + \partial_{x_t} \left[ p(x_t) \sigma^2(x_t) \right] \partial_{x_t} p(x_s| x_t) + \frac{1}{2} \partial_{x_t}^2 \left[ p(x_t) \sigma^2(x_t) \right] p(x_s| x_t) \\ = & \underbrace{\frac{1}{2} \sigma^2(x_t) \partial_{x_t}^2 p(x_s | x_t) p(x_t)}_{(1)} + \partial_{x_t} \left[ p(x_t) \sigma^2(x_t) \right] \partial_{x_t} p(x_s| x_t) + \underbrace{\frac{1}{2} p(x_s| x_t) \partial_{x_t}^2 \left[ p(x_t) \sigma^2(x_t) \right]}_{(2)} \end{align}\]by observing that the terms (1) and (2) occur in both equations. We can see from the expansion of the derivative above that we can combine the terms in our derivation if we expand the “center term”. Furthermore we can employ the identity \(-\frac{1}{2} X = -X + \frac{1}{2} X\) to obtain \(\begin{align} -\partial_t p(x_s, x_t) = & \partial_{x_t} \left[ \mu(x_t) \ p(x_s, x_t) \right] \\ & + \frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \ p(x_t) - \frac{1}{2} p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] \\ = & \partial_{x_t} \left[ \mu(x_t) \ p(x_s, x_t) \right] \\ & + \frac{1}{2} \ \sigma^2(x_t) \ p(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \underbrace{ - \frac{1}{2} p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] }_{-\frac{1}{2} X = -X + \frac{1}{2} X} \\ & \underbrace{\pm \partial_{x_t} p(x_s | x_t) \partial_{x_t} \left[ p(x_t) \sigma^2(x_t) \right]}_{\text{complete the square}} \\ = & \partial_{x_t} \left[ \mu(x_t) \ p(x_s, x_t) \right] \textcolor{red}{+ \frac{1}{2} \ \sigma^2(x_t) \ \partial_{x_t}^2 p(x_s | x_t) \ p(x_t)} \\ & \underbrace{ - p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] + \textcolor{red}{\frac{1}{2} p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right]} }_{-\frac{1}{2} X = -X + \frac{1}{2} X} \\ & \textcolor{red}{\pm \partial_{x_t} p(x_s | x_t) \partial_{x_t} \left[ p(x_t) \sigma^2(x_t) \right]} \\ = & \partial_{x_t} \left[ \mu(x_t) \ p(x_s, x_t) \right] + \textcolor{red}{\frac{1}{2} \partial_{x_t}^2 \left[ p( x_s | x_t) p(x_t) \sigma^2(x_t) \right]} \\ & \underbrace{- p(x_s| x_t) \partial_{x_t}^2 \left[ \sigma^2(x_t) \ p(x_t) \right] - \partial_{x_t} p(x_s | x_t) \partial_{x_t} \left[ p(x_t) \sigma^2(x_t) \right]}_{ - \partial_{x_t} \left[ p(x_s| x_t) \partial_{x_t} \left[ \sigma^2(x_t) \ p(x_t) \right] \right] \text{ (product rule) } } \\ = & \partial_{x_t} \left[ \mu(x_t) \ p(x_s, x_t) \right] + \frac{1}{2} \partial_{x_t}^2 \left[ p( x_s , x_t) \sigma^2(x_t) \right] \\ & - \partial_{x_t} \left[ p(x_s| x_t) \partial_{x_t} \left[ \sigma^2(x_t) \ p(x_t) \right] \right]. \end{align}\)
What remains to be done is to combine the joint probability and the conditional probability in the first order derivative terms to combine them, \(\begin{align} -\partial_t p(x_s, x_t) = & \partial_{x_t} \left[ \mu(x_t) \ p(x_s, x_t) - p(x_s| x_t) \partial_{x_t} \left[ \sigma^2(x_t) \ p(x_t) \right] \right] \\ & + \frac{1}{2} \partial_{x_t}^2 \left[ p( x_s , x_t) \sigma^2(x_t) \right] \\ = & \partial_{x_t} \Big[ p(x_s, x_t) \left( \mu(x_t) - \frac{1}{p(x_t)} \partial_{x_t} \left[ \sigma^2(x_t) \ p(x_t) \right] \right) \Big] \\ & + \frac{1}{2} \partial_{x_t}^2 \left[ p( x_s , x_t) \sigma^2(x_t) \right] \\ = & - \partial_{x_t} \Big[ p(x_s, x_t) \left( -\mu(x_t) + \frac{1}{p(x_t)} \partial_{x_t} \left[ \sigma^2(x_t) \ p(x_t) \right] \right) \Big] \\ & + \frac{1}{2} \partial_{x_t}^2 \left[ p( x_s , x_t) \sigma^2(x_t) \right] \end{align}\) the result of which is in the form of a Kolmogorov forward equation, although using the joint probability distribution $p(x_s, x_t)$. For the time ordering of $t \leq s$, we can observe that the term \(-\partial_t p(x_s, x_t)\) describes the change of the probability distribution as we move backward in time. In accordance with Leibniz’ rule we can marginalize over $x_s$ without interfering with the partial derivative $\partial_t$, to obtain \(\begin{align} -\partial_t p(x_t) = & -\partial_{x_t} \left[ p(x_t) \left( -\mu(x_t) + \frac{1}{p(x_t)} \partial_{x_t} \left[ \sigma^2(x_t) \ p(x_t) \right] \right) \right] \\ & + \frac{1}{2} \partial_{x_t}^2 \left[ p(x_t) \sigma^2(x_t) \right] \\ \end{align}\)
and introduce the time reversal $\tau \doteq 1 - t$ which, with respect to the integration with respect to the flow of time, yields \(\begin{align} - \partial_t p(x_t) = & \partial_\tau p(x_{1-\tau}) \\ = & -\partial_{x_{1-\tau}} \left[ p(x_{1-\tau}) \left( -\mu(x_{1-\tau}) + \frac{1}{p(x_{1-\tau})} \partial_{x_{1-\tau}} \left[ \sigma^2(x_{1-\tau}) \ p(x_{1-\tau}) \right] \right) \right] \\ & + \frac{1}{2} \partial_{x_{1-\tau}}^2 \left[ p(x_{1-\tau}) \sigma^2(x_{1-\tau}) \right] \end{align}\)
which finally gives us a stochastic differential equation analogous to the Fokker-Planck/forward Kolmogorov equation that we can solve backward in time: \(\begin{align} dX_\tau = \left(-\mu(x_{1-\tau}) + \frac{1}{p(x_{1-\tau})} \partial_{x_{1-\tau}} \left[ \sigma^2(x_{1-\tau}) \ p(x_{1-\tau}) \right] \right) d\tau + \sigma(x_{1-\tau}) dW_\tau \end{align}\) where \(\tilde{W}_t\) is a Wiener process that flows backward in time.
By keeping the $\sigma^2(x_t)$ constant and independent of $x_t$ and applying the log-derivative trick, the drift simplifies to
\[\begin{align} dX_\tau & = \Big(-\mu(x_{1-\tau}) + \frac{1}{p(x_{1-\tau})} \partial_{x_{1-\tau}} \big[ \overbrace{\sigma^2(x_{1-\tau})}^{=\sigma^2} \ p(x_{1-\tau}) \big] \Big) d\tau + \sigma(x_{1-\tau}) dW_\tau \\ & =\left(-\mu(x_{1-\tau}) + \frac{\sigma^2}{p(x_{1-\tau})} \partial_{x_{1-\tau}} \ p(x_{1-\tau}) \right) d\tau + \sigma(x_{1-\tau}) dW_\tau \\ &= \Big(-\mu(x_{1-\tau}) + \sigma^2 \partial_{x_{1-\tau}} \ \log p(x_{1-\tau}) \Big) dt + \sigma(x_{1-\tau}) d\tilde{W}_\tau \end{align}\]