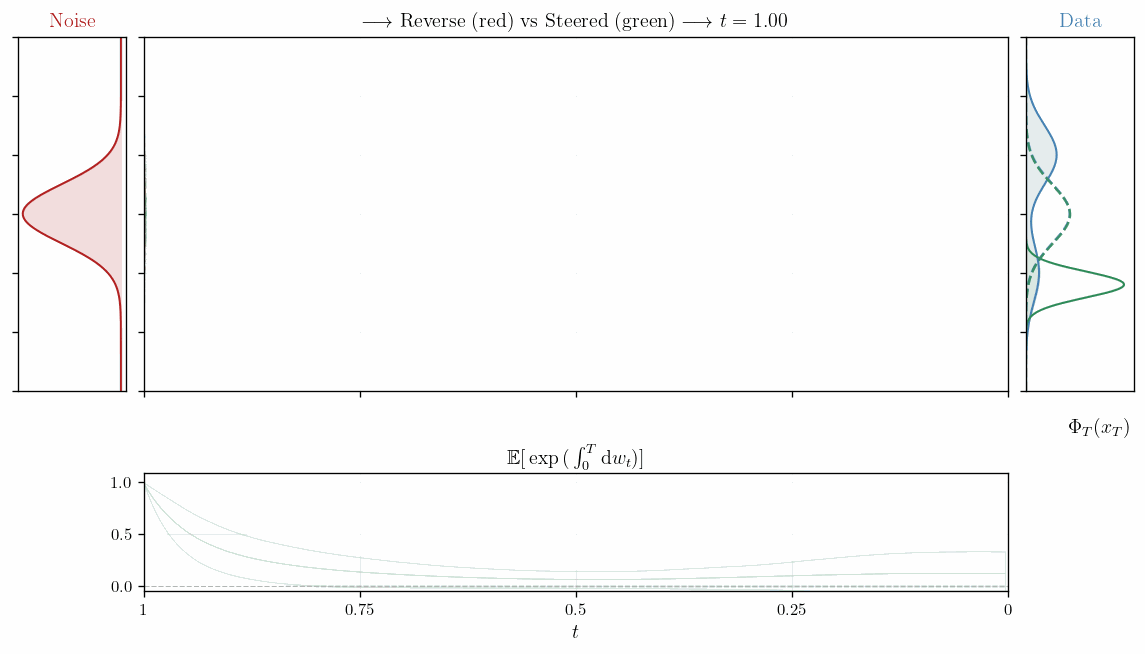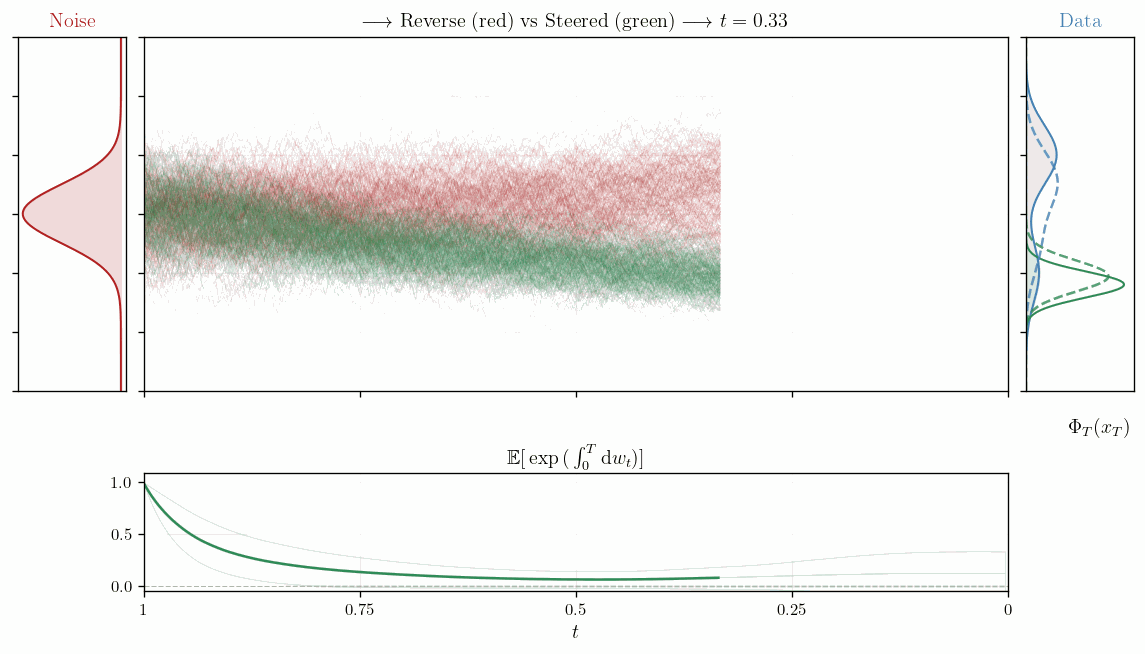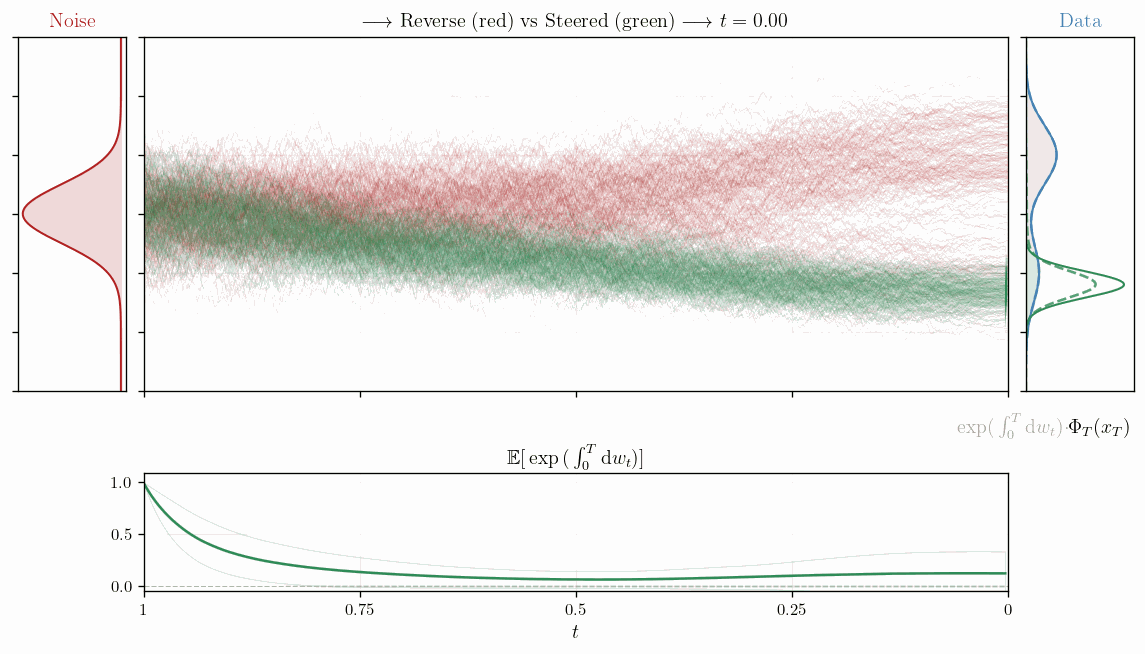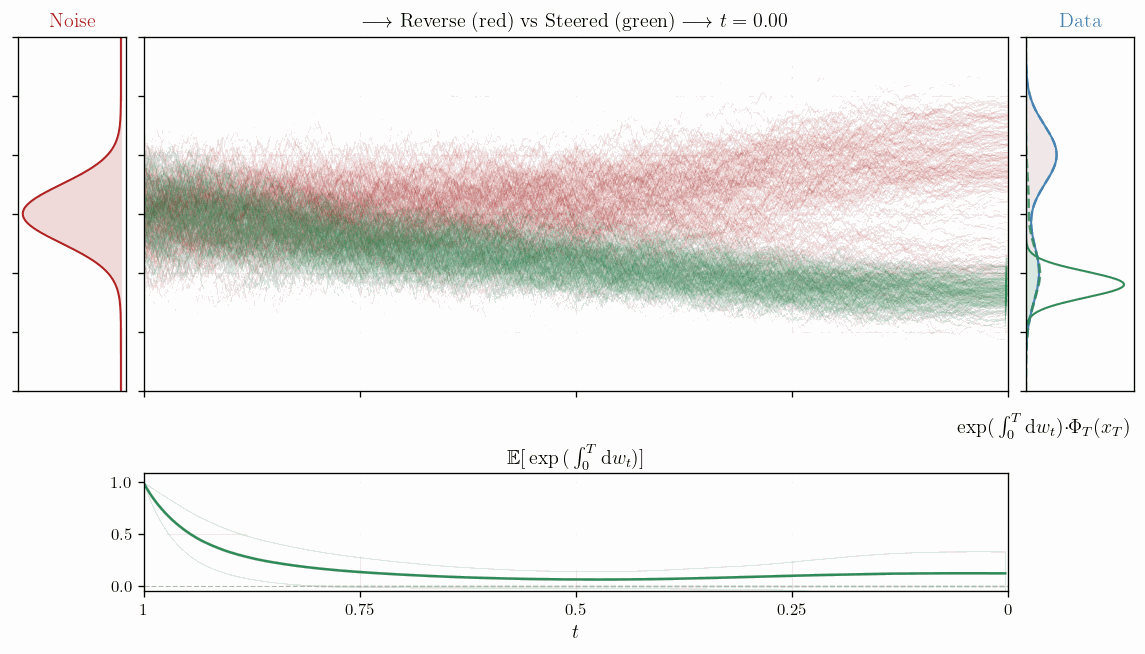
Feynman-Kac Correctors
Correct your steps.
Fokker-Planck Equation
The Fokker-Planck equation describes the time evolution of the probability density function $p(\mathbf{x}, t)$ of a stochastic process:
where:
- $\mu(x, t)$ is the drift coefficient (deterministic force)
- $\sigma^2(x, t)$ is the diffusion coefficient (related to the noise strength)
- $\nabla$ is the gradient operator
- $\Delta = \nabla^2$ is the Laplacian operator
What this essential equation tells us is how the probability density of a system’s state changes over time due to both deterministic forces (drift) and random fluctuations (diffusion). The first term on the right-hand side represents the effect of the drift, while the second term accounts for the diffusion. If we compute $\partial_t p(x,t)$ for a given $p(x,t)$, we can determine how the probability distribution evolves over time, which is crucial for understanding the dynamics of stochastic systems. The nice thing is that normalization is automatically baked into this equation. The total probability is conserved, meaning that if we integrate $p(x, t)$ over all possible states $x$, it will always equal 1 for all time $t$.
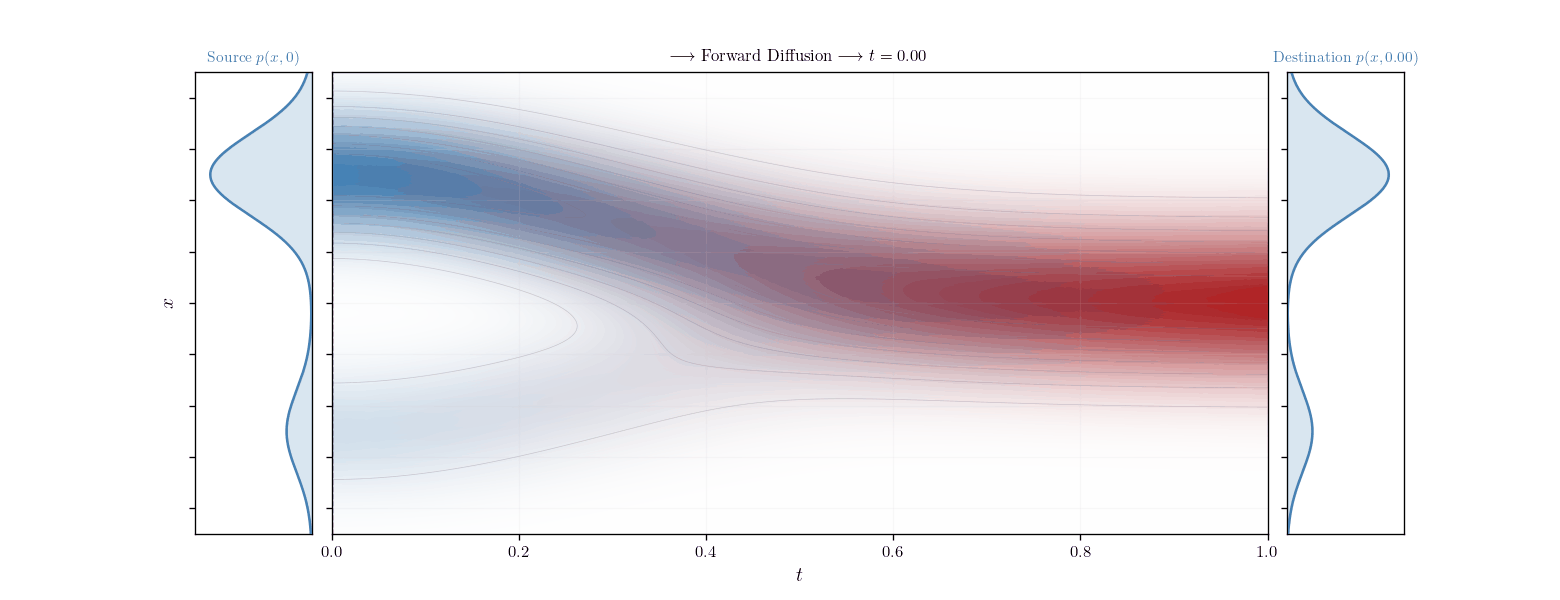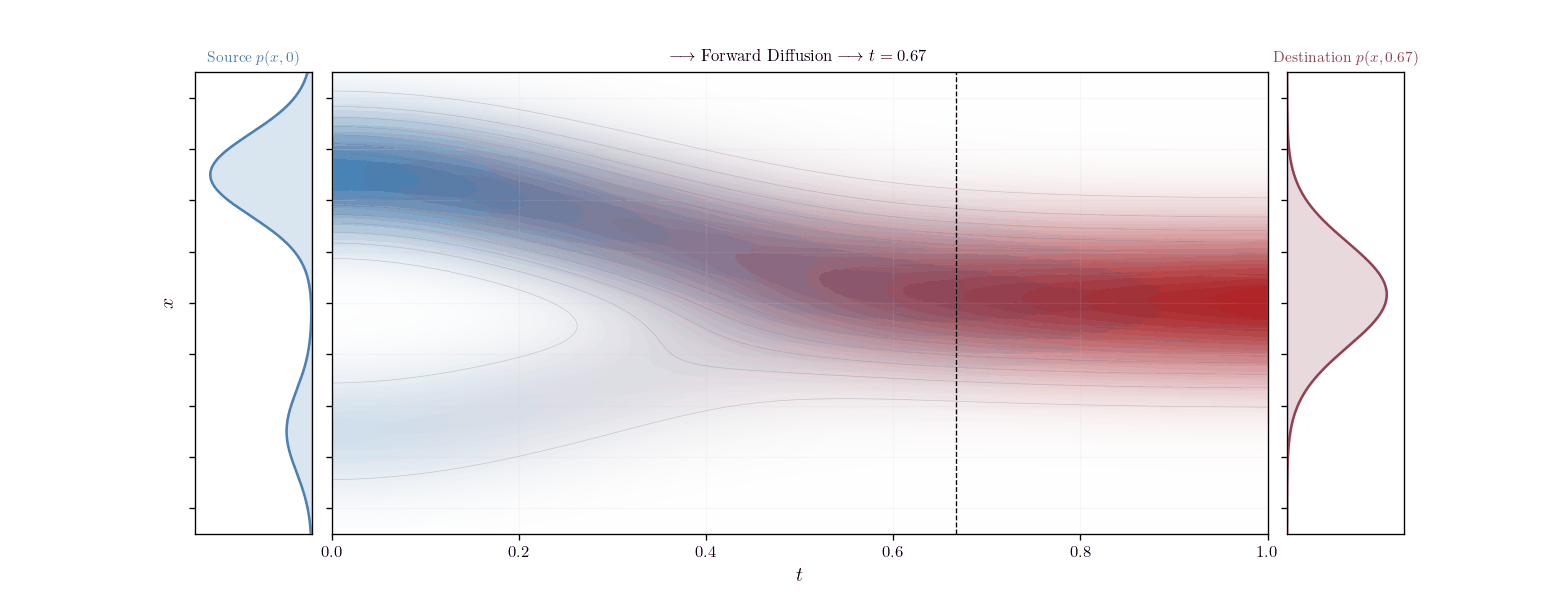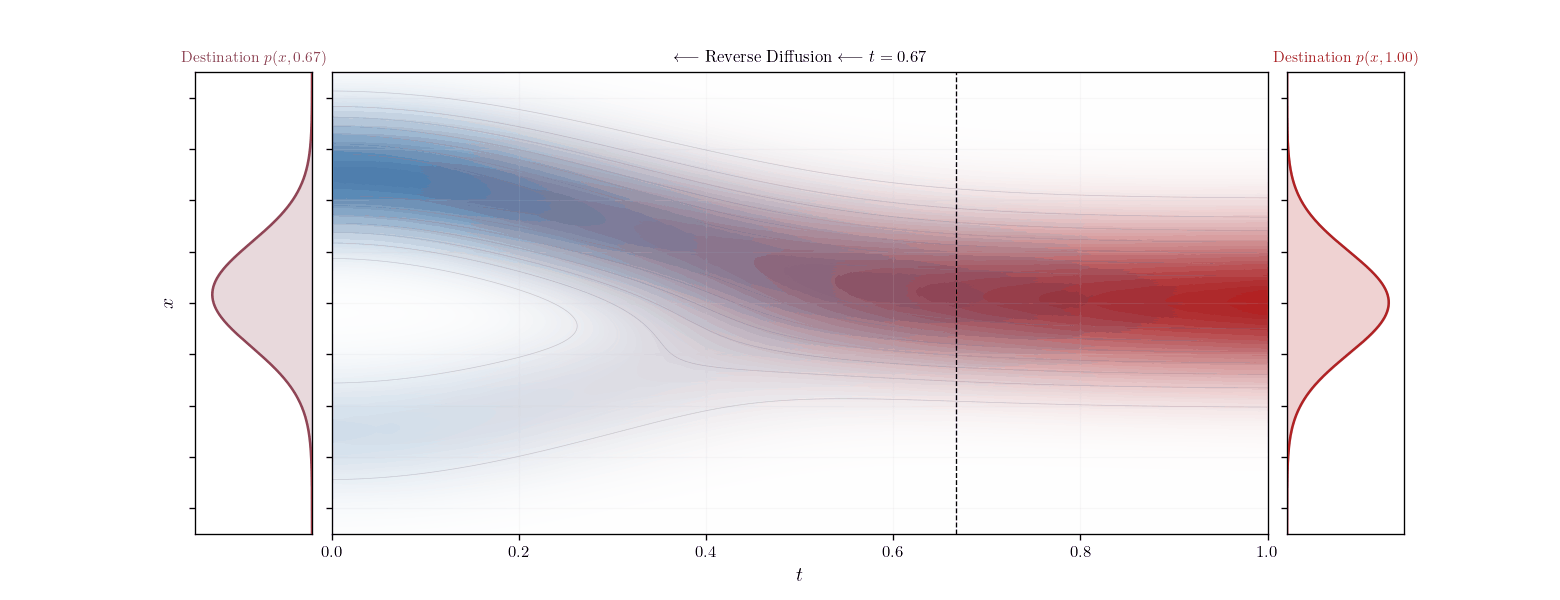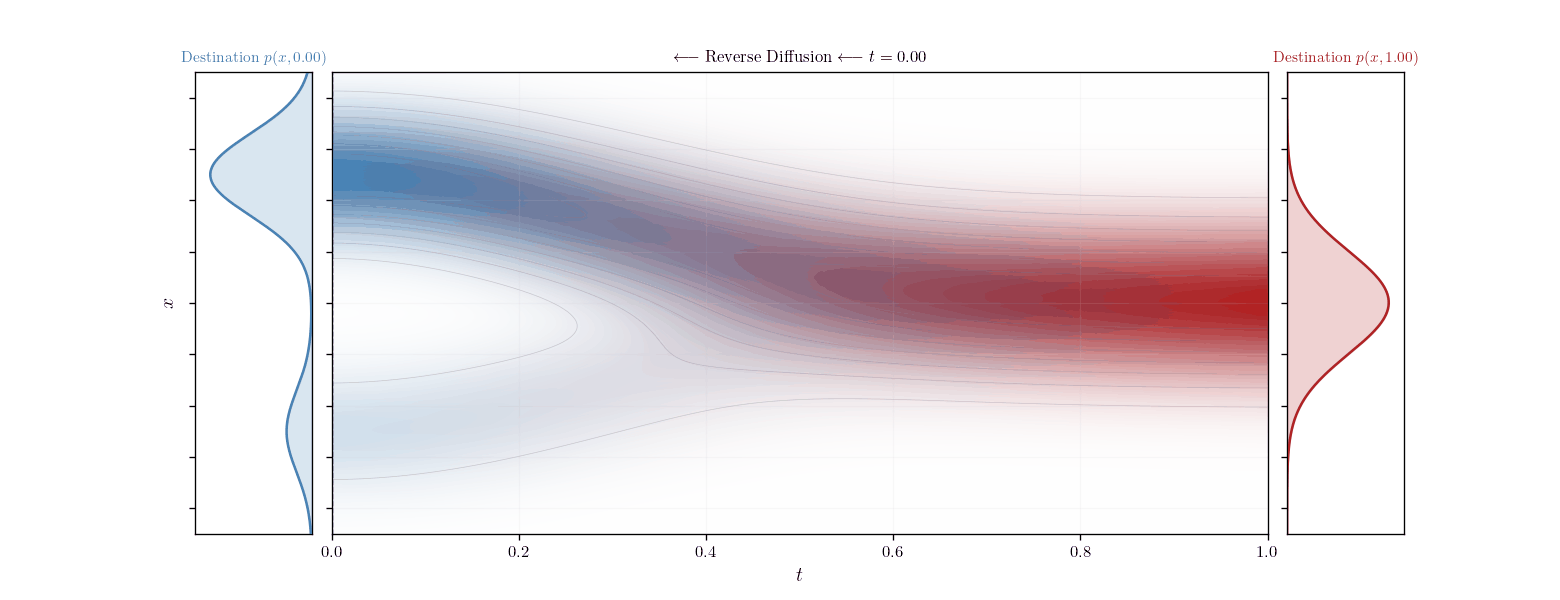
The product of distributions
The product of two distributions $p(x)$ and $q(x)$ is defined as:
Why does the integral in the denominator appear? It ensures that the resulting distribution is properly normalized, meaning that the total probability integrates to 1. The product $p(x) q(x)$ represents the unnormalized joint distribution and therefore has the correct shape, and dividing by the integral $\int p(x’) q(x’) dx’$ normalizes it to become a valid probability distribution.
Reward Tilted SDE
We consider the product of the original distribution $q_t(x)$ and an exponential of a reward function $r_t(x)$, scaled by a factor $\beta_t$:
The big question is: what is the Fokker Planck equation of $p_t(x)$ from which we can easily read off the SDE if the process evolves according to the original process dynamics of $q_t(x)$? Said differently, what’s the probability of a sample $x$ under the tilted $p_t$ if it evolves according to the stochastic differential equation of $q_t$?
So we need
where $\mu$ and $\sigma_p^2$ are the drift and diffusion of the SDE that generates $q_t$.
In order to obtain the FPE for the tilted distribution $p_t(x)$, we will exploit the FPE in log space, which offers some nice algebraic advantages. To realize that we seek to obtain the log FPE, namely not $\partial_t p_t(x)$, but
FPE in log space
Let us first recall the log-derivative trick which we will use extensively in the following calculations. For any function (or distribution) $q_t(x)$, we have the following identities:
This allows us to substitute all the gradient calculations in the FPE of our original process $q_t$ with the log derivatives,
The term $\partial_t \log q_t$ is log transformed Fokker Planck equation and governs the evolution of the original distribution $q_t$ in log space.
How $q_t$ (or $\log q_t$) evolves over time is determined by the drift $\mu_q$ and the diffusion $\sigma_q^2$ of the original process. We’re able to model that with the FPE of the original process $q_t$, but here we’re actually interested in the dynamics of $p_t$. So the question is whether we can somehow massage the term
into the form of the FPE from which we can then read off the drift and diffusion of the SDE the tilted process $p_t$.
In fact, we can express the change $\log q_t$ in terms of the sought-after process $p_t$ by rearranging the terms,
The derivatives of $\log q_t$ are
Substituting these into the log FPE of $q_t$ gives us
And what do we spy with our little eyes? The first four terms are actually the log FPE of $p_t$ itself!
We we plug in $\partial_t \log q_t$ into $\partial_t \log p_t(x)$, we get
In order to go back to the non-log FPE, we just have to multiply both sides by $p_t$ and apply the log derivative identities from above in reverse,
The last thing is how we actually compute $\partial_t \log Z$. We can compute $\partial_t \log Z$ by differentiating the definition of $Z$. For notational simplicity, let us define $\tilde{p} = \int q_t \exp(\beta_t r(x)) dx$
It should immediately be obvious that the term $\partial_t \log q_t + \partial_t \beta_t \ r(x)$ is the same term into which we’ve inserted the log derivatives. So we expand the $\log q_t$ in the same way as we did above, and then multiply it with the $p_t$ in the integral, we get
which is literally just repeating the same steps that we did above to transform the log FPE to the FPE.
One of the key properties of the Fokker-Planck equation is that it conserves probability, meaning that the total probability integrates to 1 for all time $t$. So if we integrate all the outflows and inflows of probability across the entire state space, they should balance out to zero, ensuring that the total probability remains constant. If at any time step $t$, the change in probability $\partial_t$ over the entire space $x$ would not be zero, it would imply that probability is either being created or destroyed, which violates the fundamental principle of probability conservation. So if from one $t$ to the next $t+dt$, all the changes in probability across the state space would be $-0.1$, it would imply that the total probability has decreased by 0.1 which would render our distribution $p_t$ invalid as it would no longer integrate to 1.
But in fact, we can show this analytically by integrating the FPE of $p_t$ over the entire state space. For the left hand side, we have
where we’ve used Leibniz rule where we can interchange differentiation and integration for different variables. For the right hand side of the FPE, we have
Using integration by parts,
we can exploit that fact that for any reasonable probability distribution $p_t$, the probability density at the boundaries of the state space should be zero, meaning that $\lim_{x \to \infty} p_t(x) = 0$ and $\lim_{x \to -\infty} p_t(x) = 0$.
Thus we have,
where we’ve used the fact integration and derivatives cancel each other out while preserving the boundary evaluation conditions of $p_t$ at $\pm \infty$.
We can also play the integration by parts game one more time and show that
All of this let’s us rewrite the FPE of our tilted distribution $p_t$ as
Is it in fact quite interesting that the change of probability equation that we’ve derived consists of two different parts: the original FP equation of $p_t$ and an additional term that captures the effect of the reward tilt on the probability distribution.
The first term consists only of the original drift $\mu_q$ and diffusion $\sigma_q^2$ of the original process $q_t$, which implies that we can model the original SDE as is. It is only the second term that introduces the effect of the reward tilt, modifying the probability distribution according to the function $g(x)$. Every term in the second part $g(x)$ contains in fact the reward function $r(x)$, whether it be $r(x)$ directly or its gradients $\nabla r(x)$ and $\Delta r(x)$, which means that the reward function is the only source of change in the probability distribution $p_t$.
The Feynman-Kac Equation
The Feynman-Kac equation is a fundamental result that links partial differential equations (PDEs) to expectations of stochastic processes. For a function $p$ satisfying certain boundary conditions, it defines a PDE.
For a SDE for a particle $x_t$ defined as
We can define two key operators: The first one is the the generator that acts on the test function and describes its instantaneous rate of change of the test function $\theta$ along the paths of the SDE. We’ve seen this in the Feynman Kac equation where we used it to define
where the FK equation is defined as $\partial_t \phi +\mathcal{L}_t[\phi] + g \ \phi = 0$.
The adjoint generator acts on the probability distribution $p$ and describes how the probability distribution evolves over time under the dynamics of the SDE. It is defined as
Both generators are linked through the identity
Now, we’re interested in some test function on $x$ that we name $\phi(x, t)$ and we’re interested in what the distribution of $\phi(x,0)$ and the end of our reverse diffusion process is. We have defined the probability evolution of $p$ to be governed by the Feynman-Kac PDE,
This tells us how the probability distribution $p_t$ evolves over time under the influence of both the original dynamics of the SDE (captured by the first two terms) and the reward tilt (captured by the last term).
Connecting it to the Feynman Kac equation
In a previous blog post on the Feynman-Kac equation, we saw that for very particular PDE that are defined in the state space of the SDE, we can express the solution of the PDE as an expectation over the trajectories of the SDE. Namely, we have a PDE of the form
subject to the terminal condition $u(x,T) = \Phi_T(x)$, then the solution of this PDE is given by the Feynman-Kac formula. A straightforward option would be to evolve this very particular PDE backward in time form $T$ to an earlier $t$ and then read off the solution at $t=0$. This would give us $u(x,t)$.
If the dynamics of $x$ are governed by the Ito drift-diffusion process defined above, then the solution of the PDE is given by the Feynman-Kac formula
where the expectation is taken over all trajectories of the SDE that start at $x$ at time $t$ and evolve according to the dynamics of the SDE until time $T$ with values $x_T$.
We now have two differential equations
The samples $x$ evolve according to the $dx = \mu_t dt + \sigma_t dW_t$ and induce the stochastic process $q_t$ but we’re interested in the distribution $p_t(x) = \frac{1}{Z} q_t(x) \exp(\beta r(x))$ and want to know how likely it is to sample $x$ from $p_t$ if we evolve according to the SDE of $q_t$. The function $g$ consists almost exclusively of terms that contain the reward function $r(x)$, which nicely shows that any change in the probability distribution $p_t$ is solely due to the reward tilt encapsulated in $g$.
Let’s assume a test function $u(x,t)$ with some terminal condition $u(x,T)$ and we evolve it backward in time according to the Feynman-Kac PDE over the trajectories of the SDE defined by $\mu$ and $\sigma$. As we’re evolving some terminal function backwards in time, this is obviously very closely linked to the Kolmogorov backward equation.
The question the FKC correctors try to answer is: Given my samples $x$ generated from $q_t$ but tilted towards some reward function $r(x)$, what is the expectation of $u(x,T)$ if I were to evolve further from $t$ to $T$ according to the original SDE of $q_t$?
We’re interested in the expectation
In the equation above, $q$ generates the samples $x$ according to the SDE, $r(x)$ tilts our distribution towards higher rewards such that our samples $x$ should exhibit certain characteristics favoured by $r(x)$ and then we want to know the expected value of $u(x,T)$ under this tilted distribution.
Now we can ask ourselves how $\int u(x,T) \ p_T(x) dx$ evolves over time. To make things a tad easier, we’ll for now just consider the unnormalized distribution $\tilde{p}_t(x) = q_t(x) \exp(\beta_t r(x))$ and then we can later on divide by (some estimate of) $Z_t$ to get the normalized distribution $p_t$. Fortunately, every component in $\partial_t p_t$ is a function of $p_t$, so we extract $1/Z_t$ out of every component to get
The proof for this is in the FKC paper, but it is quite intuitive if you think about it. The original FPE of $p_t$ is linear in $p_t$, so if we replace $p_t$ with $\tilde{p}_t / Z_t$, we can just pull out the $1/Z_t$ from every term and get the FPE of $\tilde{p}_t$. The authors show the consistency of this in the appendix.
Thus we’re want to know
behaves. Using Leibniz rule, we can interchange differentiation and integration for different variables, which gives us
The integration by parts substitution is a pure algebraic busy work and I skipped it here. It’s just applying the product rule many times to fully separate every term, then applying integration by parts to every term by pulling in $u$ and recombining the terms.
Integrating the dynamics from $0$ to $T$ gives us
All that remains is substituing back the Feynman-Kac formula for $u(x,0)$ and substituting $\tilde{p}_t = p_t Z_t$, which gives us
Since at $t=0$, we have $p_0(x) = q_0(x) \exp(\beta_0 r(x)) / Z_0$ with $\beta_0 = 0$ we get $p_0(x) = q_0(x) / Z_0$ with $Z_0 = 1$, we can simplify the right hand side to get
This is pure importance sampling on a trajectory level, where we sample trajectories from the original SDE, calculate $g(x_s, s)$ along the trajectory and simply integrating it in log space as a simple sum over the time steps. In the SMC blog post we saw that we can use the weights from SMC to estimate $\hat{Z}_T = 1/K \sum_k^K \exp(\int_0^T g(x,s) ds)$, which gives us a practical way to compute the expectation of $u(x,T)$ under the tilted distribution $p_T$ by sampling trajectories from the original SDE and weighting them according to the reward tilt encapsulated in $g$.